Predicting Bank Customer Attrition
A financial behavior analysis project that applies PCA, classification, and clustering to understand and predict customer churn in the banking sector.
Project Overview
This project analyzes customer attrition in the banking sector using a publicly available dataset. It applies Principal Component Analysis (PCA) to reduce feature complexity, Logistic Regression and K-Nearest Neighbors (KNN) to classify churned customers, and K-Means Clustering to segment clients based on their financial behavior. The objective is to uncover key patterns driving attrition and provide actionable insights to support retention strategies and decision-making.
Objectives
1. Dimensionality Reduction: Use PCA to reduce numerical features while retaining at least 90% of variance. 2. Classification: Compare Logistic Regression and KNN to predict customer churn. 3. Clustering: Segment customers using K-Means based on spending and credit usage.
Dataset
• Title: Bank Customer Churn Prediction Dataset
• Source: Kaggle
• Format: CSV, 10,000+ records, 23 attributes
• Target Variable: Attrition_Flag
Key Techniques
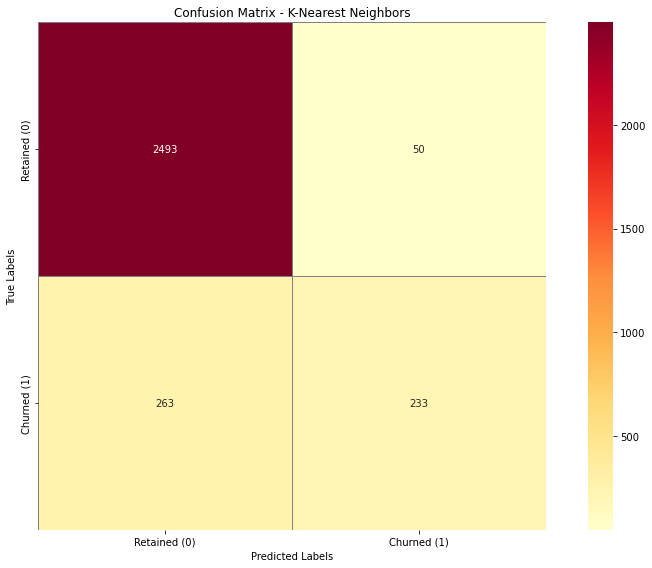
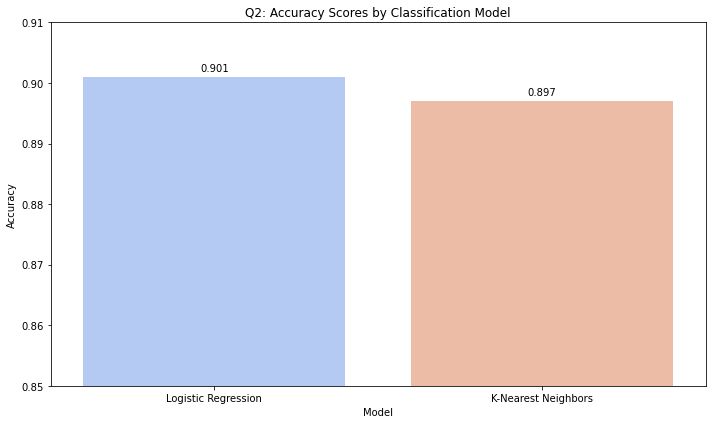
• Data cleaning: removed ID, encoded categoricals, scaled numerics • PCA: Reduced from 20+ features to 12 while retaining 90% variance • Classification: - Logistic Regression: 90.1% accuracy, better F1 for churners - KNN: 89.7% accuracy, slightly better precision • Clustering: K=4, Silhouette Score=0.19 - Profiles based on engagement, spending, and credit
Results Summary
• PCA reduced dimensionality to 12 components with minimal loss
• Best model: Logistic Regression
• 4 key clusters found with varying risk and value